

In the early days of computing, all instruction sets were based on a complex architecture called CISC. This acronym stands for Complex Instruction Set Computing and refers to the way that individual instructions are composed of multiple steps. While this approach made it possible to create powerful processors, it also resulted in slower execution times. In the 1980s, engineers at IBM developed a new type of processor architecture called RISC, or Reduced Instruction Set Computing. This approach relied on simpler instructions that could be executed quickly and efficiently. As a result, RISC-based processors became popular in desktop and laptop computers. RISC has recently become increasingly common in mobile devices and servers.
Useful types of computer architecture
The Von Neumann architecture, named after mathematician and early computer scientist John von Neumann, is a design blueprint for an electronic digital computer with these components:
- CPU: The arithmetic logic unit (ALU) performs arithmetic and logical operations.
- Memory: External storage devices include primary storage (RAM) and secondary storage (disks).
- Input/output (I/O): Communication with the outside world is managed by input/output devices.
The Harvard architecture is a computer architecture with physically separate memory systems for code and data. It is also known as the separation cache architecture or split-cache architecture. It is used in many CPUs to improve performance.
The advantage of the Harvard architecture over the Von Neumann architecture is that the Harvard architecture can have a dedicated cache for instructions and another separate cache for data, allowing each to be optimized separately. This can lead to better performance, especially in systems where the instruction and data caches have different latency characteristics.
The disadvantages of the Harvard architecture include:
- More expensive to implement due to the need for two separate caches.
- Code and data caches must be kept synchronized, adding complexity to the design.
- Some programs, such as those that use self-modifying code, may not work properly on a Harvard architecture machine.

The Princeton architecture is a computer architecture where the ALU and control unit are combined into a single unit called the central processing unit (CPU). The advantage of this design is that it can reduce the overall cost of building a computer since fewer components are needed. The disadvantages of the Princeton architecture include:
- Increased complexity due to the need to integrate two previously separate units.
- The ALU and control unit may have different latency characteristics, which can lead to lower performance.
- Programs that use self-modifying code may not work properly on a Princeton architecture machine.
The x86 architecture is a 32-bit microprocessor architecture that Intel originally designed. The advantage of the x86 architecture is its compatibility with a wide range of software, including legacy software designed for older 16-bit processors. The disadvantages of the x86 architecture include:
- Increased complexity due to the need to support a large number of legacy instructions.
- Programs that use newer 64-bit instructions may not work properly on an x86 processor.
The ARM architecture is a 32-bit microprocessor architecture that Acorn Computers originally designed. The advantage of the ARM architecture is its low power consumption, which makes it well suited for mobile devices. The disadvantages of the ARM architecture include:
- Limited software compatibility due to the lack of a large installed base of ARM-based computers.
- Programs that use newer 64-bit instructions may not work properly on an ARM processor.
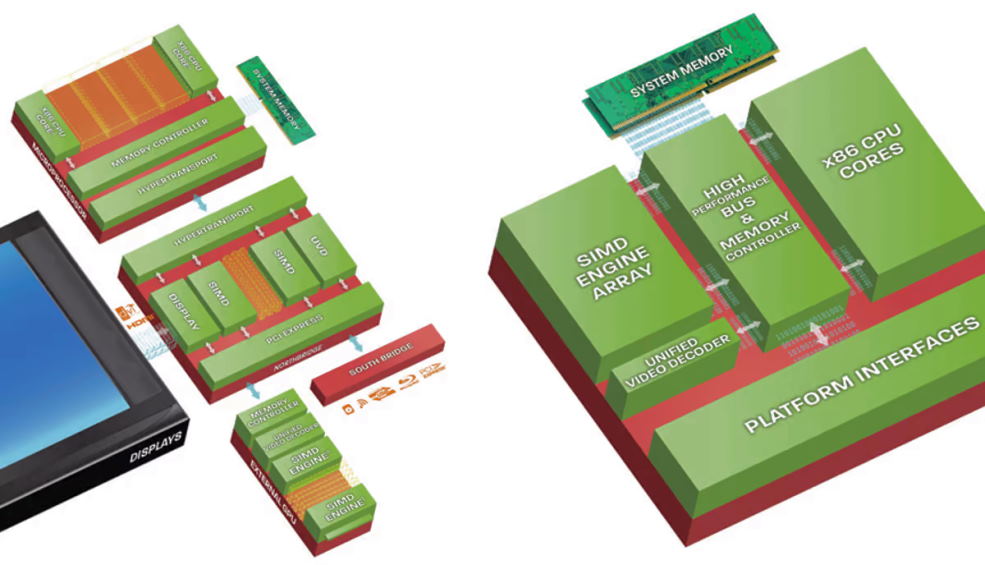
A programming model and processor architecture for next-generation, high-performance computing systems
The new programming model and processor architecture are designed to enable a higher level of parallelism and scalability than current systems. The goal is to provide a more efficient way to utilize the available computing power and to allow for a more flexible and scalable system design. In addition, the new architecture is intended to reduce the complexity of programming and make it easier to port code between different architectures.
The first step in this process is to identify the workloads most suited for this type of system. Once these have been identified, the next step is to develop a custom instruction set tailored specifically for those workloads. This approach enables a much higher degree of parallelism than is possible with traditional instruction sets, and it also reduces the complexity of code development and porting.
The new architecture is based on a number of principles:
Data parallelism: Workloads are divided into many small tasks that can be executed in parallel. This approach maximizes utilization of the available processing power and enables a high degree of scalability.
Single-instruction, multiple-data (SIMD) instructions: Specialized instructions are provided that can operate on multiple data elements in parallel. This enables more efficient execution of SIMD workloads.
Fine-grained control over resource usage: The processor architecture provides fine-grained control over the allocation of resources such as memory and computing power. This makes it possible to optimize resource usage for specific workloads.
Flexibility and programmability: The architecture is designed to be highly flexible and programmable, making it easy to port code between different architectures.
The new architecture is intended to be compatible with existing software and hardware standards, so the industry can easily adopt it. In addition, the architecture is designed to be extensible, so that future innovation can be easily integrated.
This project aims to develop a prototype system that demonstrates the feasibility of the new architecture. The prototype will be used to evaluate the architecture’s performance and refine the design. Ultimately, it is hoped that the new architecture will lead to more efficient and scalable high-performance computing systems.

